

“Paradigm has been a vogue word of the past twenty years, all thanks to Kuhn.”
— Ian Hacking, Representing and Intervening (1983)
Scientists and engineers imagine two different kinds of “paradigm shifts.” The first sort is the one we have Kuhn to thank for. It is a sudden and total reconceptualisation driven by theory in which an old scientific framework gives way to the new. The other kind is continuous and cumulative. It proceeds through trial and error by racking up changes that improve performance. The scaling project of recent years has been the beneficiary of the second type, which isn’t really a paradigm shift at all.
This essay argues that:
The contemporary frontier AI project is theory-free search that does not proceed through revolutionary change. It is not a paradigm in the Kuhnian sense.
Within the regime, progress is driven by varying artefacts and keeping modifications that improve the performance of a given system.
If the paradigm stalls, core commitments will be protected via new ancillary practices. Should that fail to salvage the programme, a successor will be selected on the basis of utility.
Automation of AI development is a change in degree, not in kind. This means recursive self-improvement under scaling will begin as recursive theory-free search.
The threshold for discontinuous capability gains is less full automation than the move from theory-free to theory-driven development.
Trials and errors
AI developers formulate hypotheses and test them through experiments, but model-making is not a science. There is no comprehensive theoretical account for why systems behave as they do. Scaling laws described an empirical regularity (that loss falls predictably with scale) before a widely held theory about why this is the case. The transformer, the closest thing to paradigmatic change in Kuhnian terms, was the product of empirical exploration rather than theoretical intuition.
The essential aspects of frontier development get by just fine without scientific accounts, by which I mean explaining why something works according to an established theory. As Noam Shazeer memorably put it: “We offer no explanation as to why these architectures seem to work; we attribute their success, as all else, to divine benevolence.”
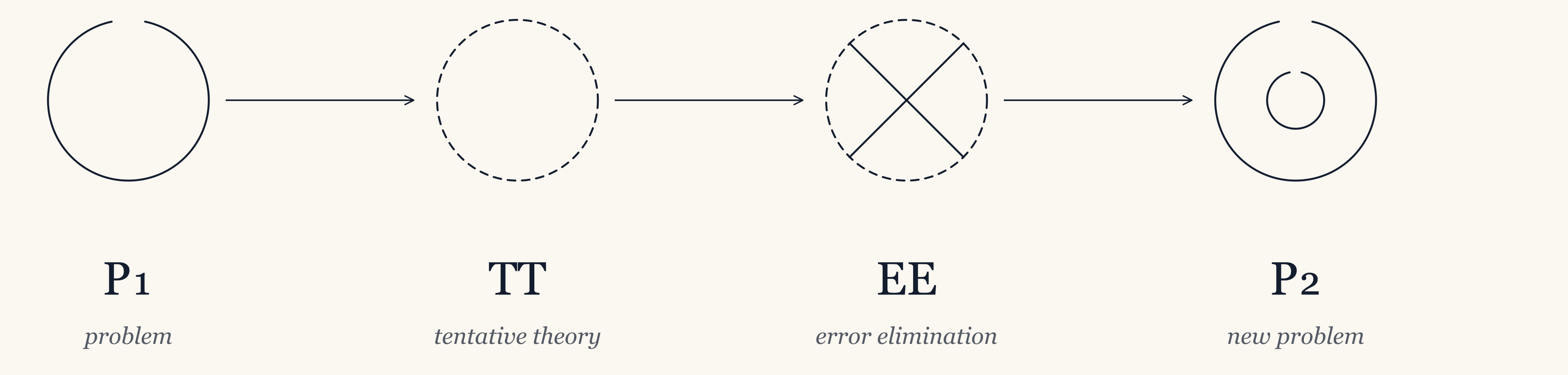
Science may also be “trial and error,” but the target of that process is theories about the world that can be refuted by the scientific method. It proceeds from P1 → tentative theory → error elimination → P2. Where science’s trials are explanatory conjectures, engineering’s trials generate variations of an artefact. Where science selects for truth, engineering selects for utility.
A future advance in development may turn on the introduction of new theoretical accounts of statistical learning, but the scaling project as it exists today neither engages this kind of effort nor needs to. The vast majority of transformative capability gains are products of engineering, with scientific inquiry serving as the field’s retrospective attempt to align map with territory.
The automation of research will in the first instance see the rapid growth of intelligence in the sense of knowing-how (the ability to produce outputs that work) rather than intelligence in the sense of knowing-why (a theory of why this process succeeds). This state of affairs may not hold over time. The curious thing about the LLM effort is that it has created systems whose capability exceeds our best theories of them. If and when a theoretical account emerges, it may be produced by these artefacts or their successors.
Should theory-free search hit one of those walls we have heard so much about, it will organise around a new target rather than waiting patiently for a conceptual breakthrough to save the day. So long as a gradient remains to climb and resources exist to bankroll it, theoretical understanding will be surplus to requirements. It is for this reason that recursive self-improvement, at least during its early stages, is better taken as recursive theory-free search.
The relevant boundary for discontinuous capability changes is therefore a move from theory-free to theory-driven automated development, not the full automation of the existing model-making process. This particular Rubicon may be crossed soon after full automation or much later. Whatever the case, it marks the point after which the process can produce vastly more powerful systems.
It’s the parameters, stupid!
John Smeaton was one of the first civil engineers. In his assessment of the opening years of the industrial revolution, he studied Britain’s waterwheels and windmills. Smeaton altered operating conditions, such as speed or water flow, which he connected to the resulting force produced by the structure. Through the application of practical trial and error and based on the careful fabrication of scale models, he determined which changes improved performance and which did not.
This type of method is “parameter variation” or the procedure of determining the extent to which the constituent parts of a given artefact bear on its output. The method goes back at least as far as ancient Greek catapult designers, who established the best proportions for their devices by systematically altering the sizes of parts of the catapult and testing the results.
Engineers at AI companies are like medieval bridge-builders who erect their structures without understanding why they hold up. They refine their craft through introducing artefact-level variations and making incremental improvements based on successful outcomes.
The signal that tells developers whether their systems “work” is harder to extract from a frontier model than a bridge, though even in adversarial cases like reward hacking model-makers respond by ramping up variation rather than going back to the drawing board. They construct better benchmarks and render clearer proxies, both of which are exercises in parameter variation.
“Treating science and technology as separate spheres of knowledge,” wrote the historian George Wise, “appears to fit the historical record better than treating science as revealed knowledge and technology as a collection of artifacts once constructed by trial and error but now constructed by applying science.”
The parameter variation model punctures received wisdom about the relationship between science and engineering, where the former discovers laws of nature and the latter applies those laws to design artefacts. To design something well, you do not have to fully understand how it works.
This idea is similar to the observation of instances in which trial and error discovery mechanisms generate an “intellectual debt.” Where the debt account concerns the outputs we put to work in a practical sense, the theory-free search of frontier AI deals with the building of an artefact without a scientific account of its workings.
All modern technologies are based on the residue of scientific practice. This is about as unremarkable as saying that all technical practice is socially conditioned. A more productive assessment holds that some technologies emerge before specific theoretical underpinnings (e.g. steam engines predating thermodynamics), while others require theory first (e.g. atomic energy or transistors).
In the case of frontier development, the scaling project is more like the former than the latter. The performance of the models is confounding not least because, based on what we know about classical statistical learning theory, they are vastly overparameterised.
The empirical method is powerful because it provides a recipe for building stuff without needing to have a complete picture of supporting theory. As the historian of technology Walter Vincenti put it: “parameter variation provides a way to circumvent even a lack of science.”
More colourfully, Douglas Hofstadter pointed out that “Nobody who designs combustion engines worries about the fine-grained level — that of molecules. No engineer tries to figure out the exact trajectories of 1023 molecules banging into each other!” The point is that engineers are concerned with utility as opposed to theoretical explanation: a combustion engine that works is a success without an account of molecular dynamics.
Engineering and science do of course share similarities. Both conform to the same natural laws, though one deals with artefacts and the other with nature. Both also diffuse according to the same mechanisms, like textbooks, articles, journals, classroom teaching, and the free movement of people from one institution to another. These shared mechanisms led Richard Feynman to argue there was little functional distinction between the two disciplines:
“Sometimes it [science] means the body of knowledge arising from the things found out. It may also mean the new things you can do when you have found something out, or the actual doing of new things. This last field is usually called technology—but if you look at the science section in Time magazine you will find it covers about 50 percent what new things are found out and about 50 percent what new things can be and are being done.”
This is a claim about reception rather than practice. The core difference between the disciplines is the criterion that makes an output worthwhile. For science that is the extent to which a result tells us something about the natural world, while for engineering utility turns on the extent to which an artefact works.
Frontier development looks more like Smeaton’s waterwheel experiments than physics. The deep learning era of 2015-2022 is sometimes taken to be a period in which foundational research laid the foundations for the LLM project. In actuality frontier models’ main ingredients are the transformer architecture, backpropagation wearing its connectionism hat, and various post training techniques. All of them are examples of engineering, and one of them is over half a century old.
Today the labs are running expensive experiments and conjuring design heuristics by trading inputs (like pre-training corpora, architectural variants, post-training recipes, and harnesses) against outputs (such as benchmark scores, behavioural properties, uptake, and user reception). In the space between sit the procedures through which the field collectively understands well in operational terms and poorly in a theoretical sense.
Fittingly, the central activity of the LLM project is parameter variation. Huge sums of capital are being expended on the basis that the next training run will be better than the last according to a handful of changes to an old family recipe. More and higher quality synthetic data, compute efficiency measures, and algorithmic tweaks collide with an array of new kinds of post-training manoeuvres that allow developers to do more with more.
This is how we would expect a mature engineering field rich in accumulated experience to operate. The trial and error of parameter variation, enacted across enough domains with enough capital at its back, is all it takes to build capable systems.
Hardcore, do you want more?
The philosopher Imre Lakatos distinguishes between the “hard core” of a research programme, the central commitments treated as gospel, and the “protective belt” of supplementary practices through which a programme accommodates new evidence.
In the discovery of Neptune, for example, Newton’s laws formed the hard core of planetary motion. When Uranus’ orbit deviated from these predictions, French astronomer Urbain Le Verrier hypothesised an unseen planet that would account for the discrepancy. Le Verrier’s efforts represented an adjustment in the protective belt, which was immediately proved correct by Johann Gottfried Galle at the Berlin observatory in 1846.
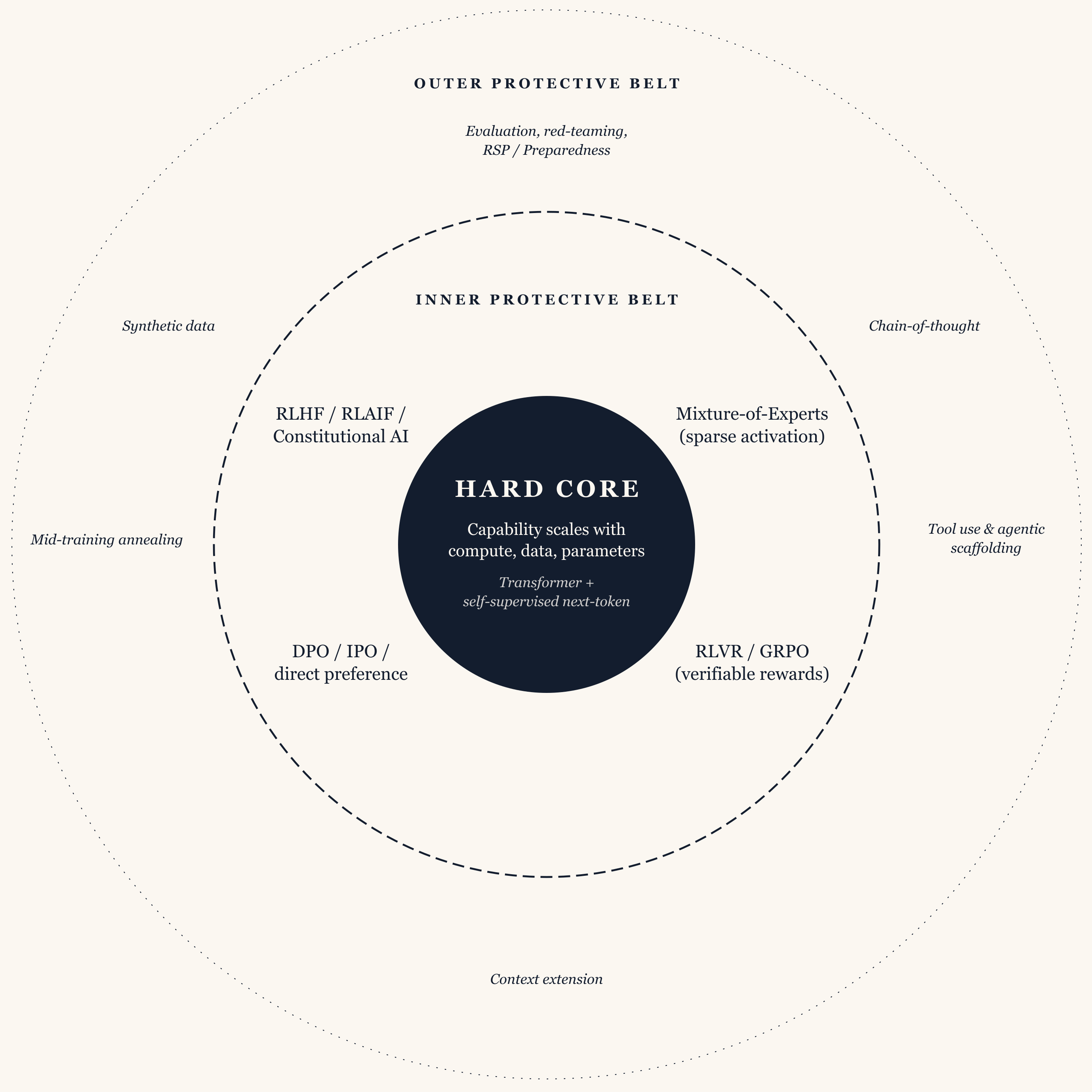
Lakatos was a philosopher of science, so I am taking some liberties in applying his model to an industrial engineering effort. I do so because this framework is useful for separating the essential and peripheral aspects of the scaling programme.
The core of the frontier AI research programme consists of a small set of commitments that frontier lab practitioners take to be foundational. The first is that greater capability can reliably be extracted from more effective compute and data without reference to a specific functional form (including at inference time).
When evidence appears to threaten the scaling commitment, whether via data exhaustion or diminishing returns at extreme scale, the field’s response has naturally been to treat it as a problem to solve at the belt rather than overturning the core i.e. to stick with essential tenets like self-supervised token prediction as opposed to betting the house on a new regime.
Another holds that the transformer architecture, or close architectural variants in the same family, is the appropriate substrate to build thinking machines. Alternative architectures like state space models have received occasional attention without displacing the transformer family from the centre of frontier development. The commitment is to the broader family of attention-based sequence models, and does not necessarily turn on the specific form of self attention described in 2017.
Two final commitments complete the core: that self-supervised learning over large text and multimodal corpora is the right learning signal in pretraining; and gradient-based optimisation in the form of first-order methods is the most suitable training procedure. An approach that abandoned these commitments would signal the start of a new search process with new learning signals.
With the core in place, advances flow from dialling up data and compute and the piecemeal business of extending and repairing the programme without disturbing its central commitments. This is more or less how the field describes its own practice.
Some fraction of frontier AI development has been automated since before the launch of ChatGPT. How much is unclear, though the majority of code merged into Anthropic’s codebase is currently written by Claude. That does not mean that Claude drives the majority of its own development, but it does mean that it is responsible for more than none.
Anthropic recently suggested that:
“AI is rarely advanced by “eureka!” moments. There have been a few of these in AI’s recent history, like the Transformer architecture, or mixture-of-experts models, but paradigm-shifting ideas arrive years apart. In between, most progress is incremental: we scale something up, see what breaks, fix it, and try again.”
This passage evokes Kuhn’s famous “normal science” framework in which business as usual puzzle solving is punctuated by revolutionary changes in programme structure that open up new secondary and tertiary problems.
But none of the “paradigm-shifting ideas” since the transformer, including mixture-of-expert architectures, have been paradigm-shifting in a Kuhnian sense (not least because frontier AI is not a scientific programme). And they are not puzzle solving either, since normal science assesses its solutions by their fit with an existing theory of the world. Both require a theory-dependence that the contemporary AI project does without.
A better way to describe the LLM programme is as an engineering process in which every incremental change and every eureka moment of the last five years has been an exercise in parameter variation. The consequential developments emerged from the same empirical milieu that produces the gradual progress on which the rest of the effort depends. They were found by varying the recipe and keeping or emphasising the parts that most significantly influenced performance.
Crucially, inclusion in the core does not turn on the influence of a particular programme element. Chain of thought methods to leverage compute at test time are hugely important, but if they stopped paying off tomorrow, the field would go looking for another way to convert compute into capability at inference time.
Search century
Parameter variation under any given regime cannot go on indefinitely, and there are points at which a programme either reorganises around a new set of variables or is replaced by some other project less likely to run out of road.
Labs will ‘throw proposals at the wall’ until something sticks, and those projects, whatever their method, will be selected on the basis of utility. If the frontier experiment gets stuck in the mud, the next regime will engage a proposal that the existing search apparatus can be directed towards. Scientific accounts are not required for a new search effort any more than within an established programme.
But the LLM effort is in some sense different in kind from engineering projects of the past. It needs only to complete the automation of the development process that is already underway to consider its job done. Parameter variation, that is, adjusting the belt while the core remains intact, is already partly automated. Recursive self-improvement will begin as an extension of the scaling programme, including the belt and core as it currently exists.
If full automation occurs under the large model project or a successor regime, development will look, at least in its opening stages, like recursive parameter variation. The target for automation is the theory-free search that already defines frontier development.
Recursive self-improvement under scaling will not begin as an explosion of intelligence-as-understanding, with each system reasoning its way to a position deep enough to design the next. Self-improvement will begin as the automation of theory-free search.
That does not mean that there is no underlying logic, only that there is some unknown theory and therefore uncertain failure modes and fuzzy timelines. It can proceed so long as it has a rough sense of where to look next, say, in terms of architectural variants or mixtures of data.
The search space is not infinite, but it is extremely large. Making meaningful progress across a vast area of possible configurations depends on a) how much of the space we are able to cover and b) how good we are at choosing where to look. The first is primarily a function of compute insofar as more chips buy more runs and larger models and more candidates put to the test.
The second, the question of taste, matters more in the near term for automation. Right now it’s unclear whether the discernment that directs compute can be handled adequately by a model (though in principle I do not see any reason why not).
A system that designs its successor will do what Smeaton did with his waterwheels and what the labs do right now. It will vary the approach, keep what works, eject that which does not, and repeat the process for the next turn of the screw. A model stewarding this development cycle needs no theory of why it works any more than the catapult builders of the Peloponnese needed a theory of torsion.
Takeoff, should it occur under the large model paradigm, will be a faster and less well supervised version of parameter variation. Each decision about additions or modifications will be calibrated according to weak signals drawn from inside the labs and, where essential, from commercial deployments.
Evolution shows that theory-free search is in principle capable of producing theory-capable agents. Given enough time and resources, recursive parameter variation could cycle through programmes to produce systems capable of true paradigmatic shifts. Rather than the full automation of development, this is the threshold that matters for discontinuous take-off.
Thanks to Matt Mandel, Alex Chalmers, Ashley Kim, Ben Bariach, Beba Cibralic, Nathan Darmon, Matthijs Maas, and Prakriti Bandhan for feedback on earlier versions of this essay.
Great discussion about the disconnect between logical, researched approaches and vaporware.