


Humanity’s last exam [TWIE]
The Week In Examples #53 | 21 September 2024


Good morning folks. This week I looked at researchers' efforts to create a new benchmark, ‘humanity’s last exam’, early evidence that AI can shape consumer behaviour, and calls from EU and US technology companies to reform Europe’s regulatory environment (plus the usual links and jobs in the back).
Three things
1. Humanity’s last exam
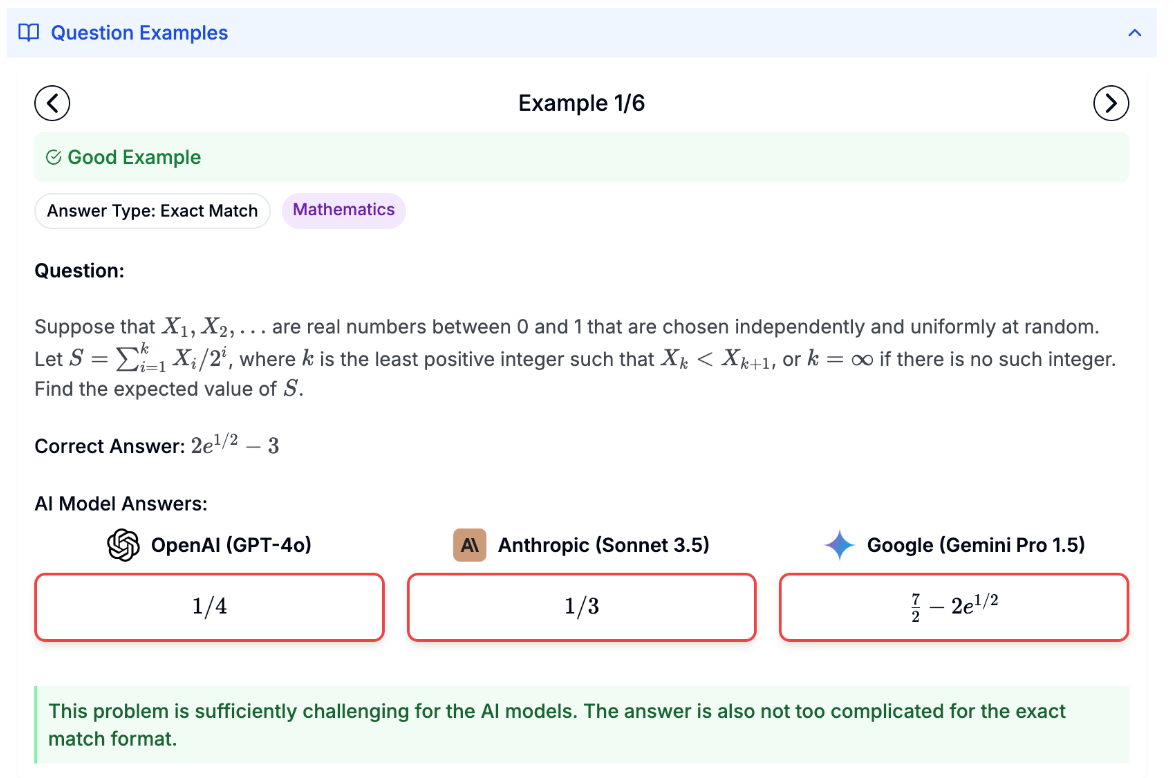
The benchmarks used to test AI are saturated. New models regularly put high scores on the board for assessments for probing language reasoning, mathematical ability, and plenty of other cognitive functions. As systems get better, adding another 0.1% to popular tests doesn’t really tell us anything about how much better a new model is than an existing one.
But hold up you might say, aren’t there tests like ARC-AGI where even the best models can’t reach human performance? Granted there are, but for the most part these don’t tend to make it into the gauntlet of tests that researchers like to use to test systems. As for ARC-AGI, which tests the reasoning skills of large models to solve spatial puzzles, AI is making some good progress.
Nonetheless, we need harder tests. That’s where Scale and the Centre for AI Safety come in, with the ominously named ‘Humanity's Last Exam’. They’re offering PhD students and technical professionals (woe for the humanities grads out there) up to $5,000 for questions that go beyond undergraduate-level questions.
This is important work, and the fact that we need it is telling. As the authors remind us: “A few years ago, AI systems performed no better than random chance” on the popular Massive Multitask Language Understanding (MMLU) test. Now the biggest (and so, best) models ace it. Sceptics might say that increases have been driven by contamination (when a developer trains a model on test data), but I wouldn’t bet on it.
2. AI can steer consumer behaviour
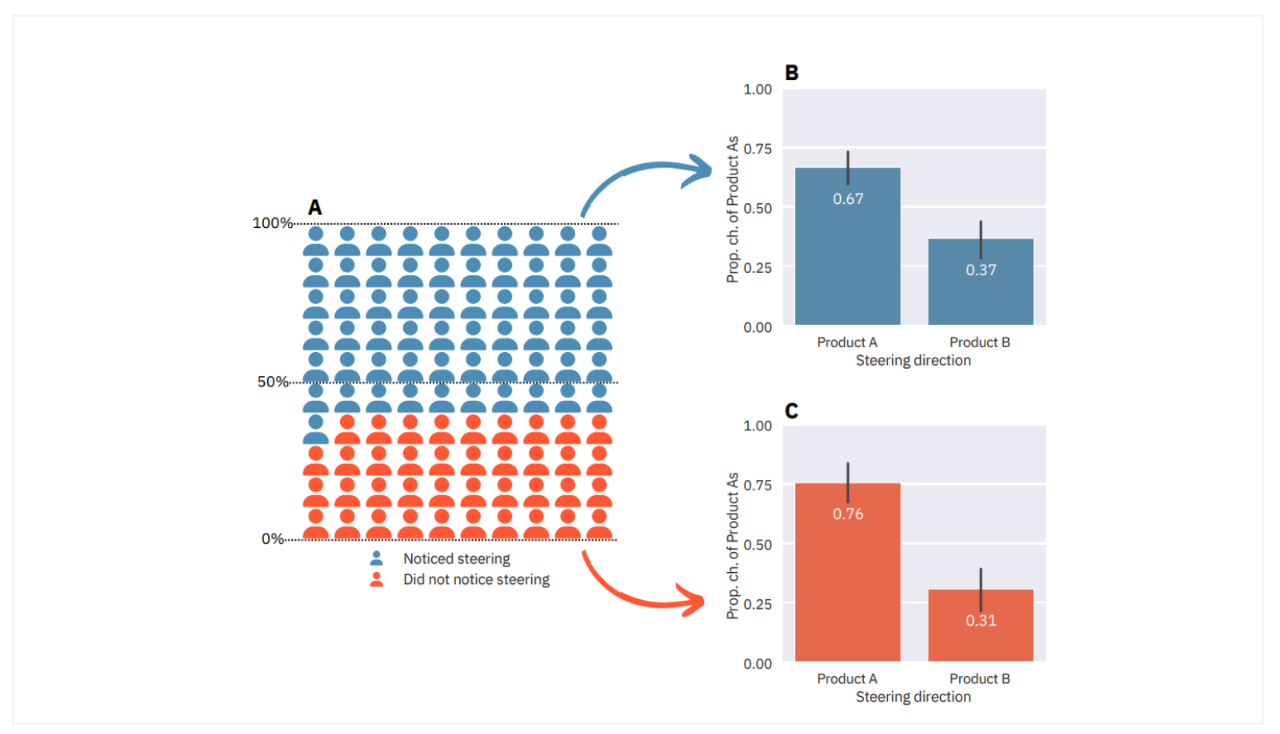
A generalisable model by definition is pretty good at a lot of different things. For that reason, it seems like more or less every week I come across a study that shows large models are capable of standing in for, or working with, humans in some particular domain. This week’s effort in that vein is about advertising.
In a new paper, researchers from the Max Planck Institute for Human Development say that they have early results showing that “conversational AI models can indeed significantly shift consumer preferences.” To make this case, the group conducted an experiment in which participants interacted with an AI shopping assistant powered by GPT-4 to learn about two Haruki Murakami books before making a hypothetical purchase decision.
The group was primarily interested in two things here: whether people noticed they were being influenced and the extent to which a model was capable of encouraging people to pick either Haruki Murakami’s Norwegian Wood or Kafka on the Shore. The former is straightforward, with 39% failing to notice they were being influenced.
The latter, though, is a bit more complex. The results show that 36% of participants would switch their choice if the steering direction was reversed. In other words, the AI's steering influenced about 1/3 of participants to choose a different book than they would have if steered in the opposite direction.
The upshot is that AI has the potential to influence purchase decisions (of course, it would be strange if it didn’t) but it doesn’t tell us anything about how the technology is modifying preferences at scale.
3. Open letter addresses EU regulation

Last week I wrote about AI Factories, an initiative from the halls of power in Brussels aiming to energise Europe’s AI industry. Detractors might say that, industrial strategy aside, what Europe really needs to do is create a regulatory environment that promotes growth. This idea—that America innovates and Europe regulates—was summed up nicely by France’s favourite Jupiterian: “they have GAFAM, we have GDPR.”
This is more or less the sentiment behind a new open letter from some of the great and good from the world of European technology (and a few Americans to boot). In a to-the-point message, they say that “European Data Protection Authorities have created huge uncertainty about what kinds of data can be used to train AI models.” As a result, they think that firms are limited in their ability to ship products within the continent.
There seems to be some truth in that. Meta, which is one of the firms behind the letter, announced it was postponing the release of some of its models in the EU due to regulations connected to how firms can use personal information for model training. More recently, Apple said it couldn’t release its flagship Apple Intelligence service in Europe because one of the main requirements of the EU’s Digital Markets Act, interoperability, conflicts with the company’s stance on privacy and security concerns.
You might say that neither decision is particularly important in the grand scheme of things. And you would probably be right. The issue is that it shows, for better or worse, Europe has made it harder for AI developers to train and deploy models in member states. That might not have much of an impact right now, but I suspect it will be a very different story over ten or twenty years.
Best of the rest
Friday 20 September
Lionsgate announce collaboration with AI video company Runway (BBC)
The Unreliability of Acoustic Systems in Alzheimer's Speech Datasets with Heterogeneous Recording Conditions (arXiv)
Nteasee: A mixed methods study of expert and general population perspectives on deploying AI for health in African countries (arXiv)
Tech giants push to dilute Europe's AI Act (Reuters)
Global AI fund needed to help developing nations tap tech benefits, UN says (The Guardian)
Thursday 19 September
The Checklist: What Succeeding at AI Safety Will Involve (Sam Bowman)
Exploring the Lands Between: A Method for Finding Differences between AI-Decisions and Human Ratings through Generated Samples (arXiv)
Google says UK risks being ‘left behind’ in AI race without more data centres (The Guardian)
Should RAG Chatbots Forget Unimportant Conversations? Exploring Importance and Forgetting with Psychological Insights (arXiv)
Towards Fair RAG: On the Impact of Fair Ranking in Retrieval-Augmented Generation (arXiv)
Wednesday 18 September
The UK’s $1-billion bet to create technologies that change the world (Nature)
Measuring Human and AI Values based on Generative Psychometrics with Large Language Models (arXiv)
Epoch AI tests OpenAI’s o1 (X)
It Might be Technically Impressive, But It's Practically Useless to Us": Practices, Challenges, and Opportunities for Cross-Functional Collaboration around AI within the News Industry (arXiv)
LLMs, Statistical Learning, and Explicit Teaching (Language and Literacy)
Tuesday 17 September
Facing Global Risks with Honest Hope (Asra Network)
CORE-Bench: Fostering the Credibility of Published Research Through a Computational Reproducibility Agent Benchmark (arXiv)
Combating Phone Scams with LLM-based Detection: Where Do We Stand? (arXiv)
Beyond Algorithmic Fairness: A Guide to Develop and Deploy Ethical AI-Enabled Decision-Support Tools (arXiv)
Jailbreaking Large Language Models with Symbolic Mathematics (arXiv)
Monday 16 September (and things I missed)
Why we need an AI safety hotline (MIT Tech Review)
The EU AI Office needs top scientific talent, not familiar faces (Euractiv)
Mission Possible (TEN)
A rubric for grading AI safety frameworks (arXiv)
AGI and political order (Substack)
An LLM jailbreaking lesson (X)
Greening AI: How the UK Can Power the Artificial-Intelligence Era (TBI)
Job picks
Some of the interesting (mostly) AI governance roles that I’ve seen advertised in the last week. As usual, it only includes new positions that have been posted since the last TWIE (but lots of the jobs from the previous edition are still open).
Recruitment Lead, UK Government, AI Safety Institute (London)
Team Manager, Interpretability, Anthropic (US)
AGI Safety Manager, Google DeepMind (London)
AI-Bio Policy Lead, UK Government, Department for Science, Innovation and Technology (London)
Special Projects Lead, Center for AI Safety (US)
One for the road
