


The cruelty of the Turing test
Weep for AI’s founding story


ChatGPT has passed the Turing test, the well known thought experiment, research goal, and philosophical quagmire (delete as appropriate) introduced by British mathematician Alan Turing in 1950. Speaking to Joe Rogan, venture capitalist and Tolkien lore aficionado Peter Thiel said:
“What happened in some sense with ChatGPT in late 2022 or early 2023 was that the achievement you got—you didn’t get superintelligence and it wasn’t just surveillance tech—but you actually got to the holy grail of what people would have defined AI as from 1950 to 2010. For the previous sixty years, before the 2010s, the definition of AI was passing the Turing test”.
But is that really true? Not only in a ‘did ChatGPT get a good score’ sort of way, but more fundamentally, is it a statement that means what we think it does once we strip away the layers of familiarity stacked atop Turing’s famous idea? Was the test designed to be practically implemented (let alone passed)? If not, how are we to make sense of one of the best-known scriptures in the AI canon?
This essay is about these questions. I don’t claim to answer them fully, but I do hope to provoke some scepticism next time you hear someone shooting from the hip about AI’s favourite target. I wrote it because a staggering amount of well informed people can’t help but misinterpret the Turing test, which has become something of a caricature attracting exuberance and derision in equal measure.
I’ll start with what it isn’t: a practical assessment that aims to look for signs of alien life machine intelligence. To explain why, this essay pieces together fragments of historical context to argue that the test was first and foremost a counterpunch in an intellectual sparring match between Turing and his greatest rivals.
The claim
Let’s start with the claim. ChatGPT has aced the Turing test, which Thiel says “we weren’t even close to passing in 2021.” I’ll get to what the test actually is and how it works, but for now, let’s take the folk version that people generally refer to as a starting point. Simply put, a human judge interacts with both a machine and a human without knowing which is which. If the judge cannot reliably tell them apart, the machine is said to have passed the test. (As we shall see, though, the judge is often removed and it becomes a two-person game.)
Based on this description, we might expect no AI system to have previously ‘passed’ the test. But that’s not quite right. We can go all the way back to the 1960s to see examples of Joseph Weizenbaum's Eliza chatbot convincing people, at least under some limited circumstances, that it was a human.
In Bots: The Origin of New Species, for example, Andrew Leonard recalls a moment in 1966 when Eliza was confused with Weizenbaum logged in from home, while Daniel Bobrow of Bolt and Newman Inc. famously described an instance in which a version of the Eliza program was mistaken for him by a company executive. Then there is of course the Loebner Prize, which since 1991 has seen some judges fooled by computer systems of various stripes. Not to mention the millions of online chatbots that I presume, like monkeys and typewriters, have successfully duped someone at some point in time.
The obvious objection to these examples is that they are anecdotes: instances in which machines have been mistaken for people only for moments, and without regard to anything like formal testing protocols. At the point at which we impose stricter conditions (for example, convincing several judges over a prolonged period of time) the success rate plummets. Fair enough. But it does beg the obvious question: what then are the conditions for success?
The answer, unfortunately, is that Turing never provided any. The reason for that, which I’ll get to a little later, is that the test was never designed to be used as a practical measure of intelligence – but it is worth saying that Turing did speculate about the capabilities of future machines faced with the imitation game. In his famous paper published in the journal Mind, he forecasted that by the year 2000 systems with a capacity of 109 bits—a tiny figure compared to today’s large models—would be able to “play the imitation game so well, that an average interrogator will not have more than a 70 percent chance of making the right identification after five minutes of questioning” (i.e. that a machine could deceive the judge in 30% of cases).
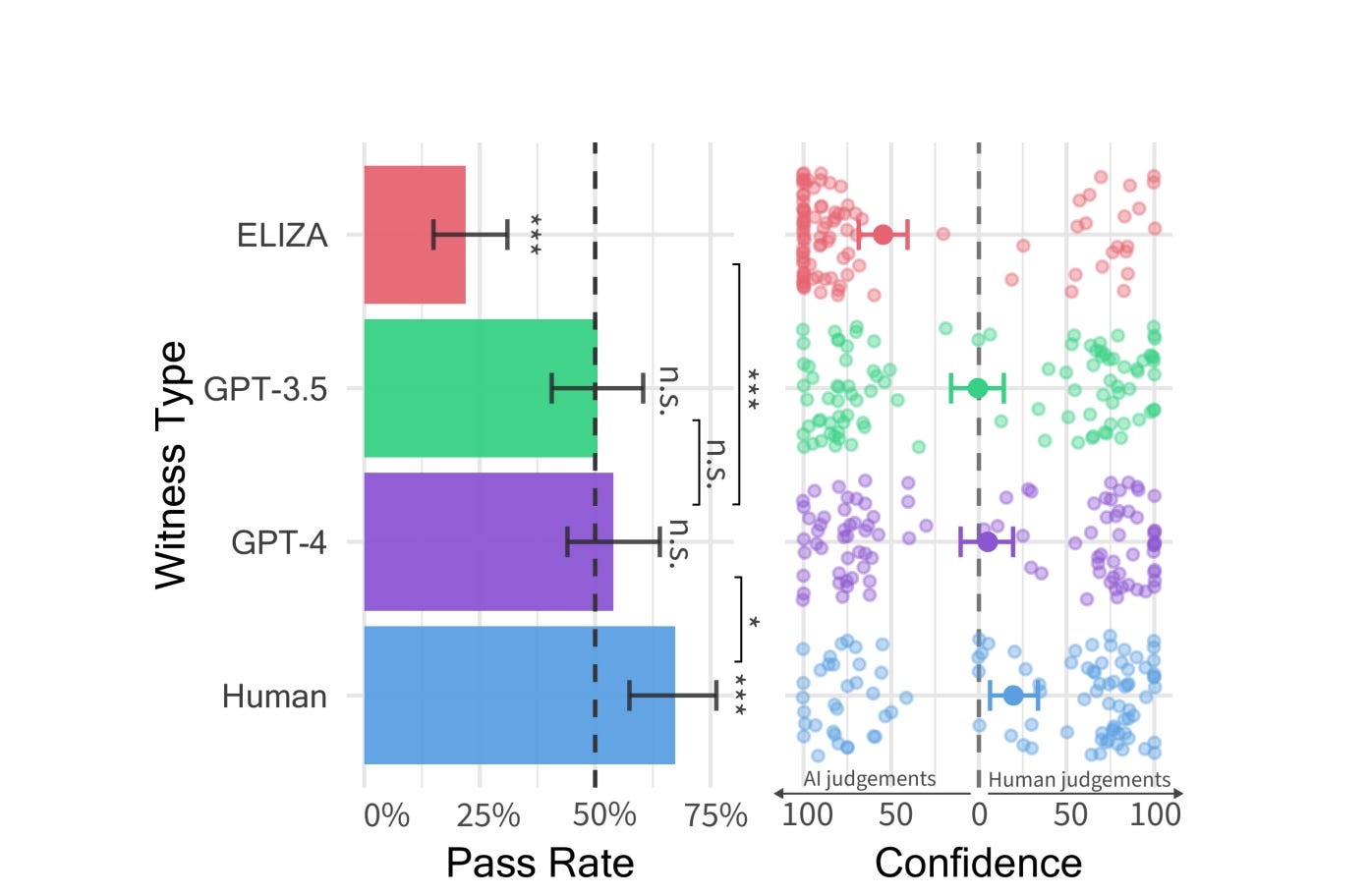
More recently, researchers from UC San Diego evaluated GPT-3.5, GPT-4, and the long-in-the-tooth Eliza by setting up a simple two player version of the game on the research platform Prolific. They found that GPT-4 was judged to be human 54% of the time, that GPT-3.5 succeeded in 50% of conversations, and that Eliza managed to hoodwink participants in 22% of chats. Real people beat the lot, though, and were judged to be human 69% of the time.
As for whether this is enough to say that GPT-4 ‘passed’ the Turing test, I’ll leave that up to you. The essential problem with the test, as the above should make clear, is that there is no agreed upon condition for success. Not from Turing, and certainly not from anyone else.
The test
As we’ve seen, people tend to play fast and loose with the format of the imitation game. More often than not the party conducting the test opts for a two player version, which—like the UC San Diego study—departs from the description given in the original paper. The initial experiment, as Turing envisioned it, was based on a game involving a man, a woman, and a judge:
“It is played with three people, a man (A), a woman (B), and an interrogator (C) who may be of either sex. The interrogator stays in a room apart from the other two. The object of the game for the interrogator is to determine which of the other two is the man and which is the woman. He knows them by labels X and Y, and at the end of the game he says either "X is A and Y is B" or "X is B and Y is A."”
Turing’s experiment swaps out one of the participants in the game for a machine. Instead of determining whether participant A or B is a man or a woman, the revised version sees the judge pick whether or not the writer is a person or a machine. If the Turing test judges intelligence, then the first imitation game assesses the ability to convincingly pass as the opposite gender.
But to take a step back, what do we think a game about whether a man could stand in for a woman (or vice versa) is actually testing? And what do we think that means for the second version of the game involving a machine? Fortunately, Turing gives us a clue:
“The original question, "Can machines think?" I believe to be too meaningless to deserve discussion. Nevertheless I believe that at the end of the century the use of words and general educated opinion will have altered so much that one will be able to speak of machines thinking without expecting to be contradicted.”
The test wasn’t designed to answer the question of whether machines can think (after all, one doesn’t make a test to answer a meaningless question). But, just like the gender imitation game, the test must be—according to Turing—fulfilled in a way that prevents a third party observer from being able to tell the difference between those involved. It’s about the rhetoric of machine intelligence, not the substance of it.
In an exchange used to illustrate how one might catch a machine out, Turing describes a back and forth in which the judge asks whether an agent could play chess (it says yes) or write a sonnet (it says no). The implication, of course, is that any sufficiently intelligent machine would be capable of engaging in creative pursuits (apologies to all the chess players out there).
The final aspect of note is the type of machine that Turing believes will be entangled with intelligence in the future. As he writes towards the end of the paper: “instead of trying to produce a programme to simulate the adult mind, why not rather try to produce one which simulates the child's?”
The history
Let’s start putting this together. We have a thought experiment that seeks to set the conditions in which someone could call machines intelligent, explicit links with gender, learning machines, and creative pursuits as essential markers of intelligence. Taken in the round, these elements should do enough to puncture the two most common interpretations of the imitation game.
First, the ‘reductionist’ view, which holds that the Turing test was developed to measure intelligence. This idea is popular with some AI practitioners, who see the test as a soluble target that should inform research. In this version, intelligence can be directly measured, and therefore the test is a legitimate aim.
Next up is the ‘constructionist’ interpretation that focuses on the idea that the test itself creates a certain type of intelligence through its design and implementation. In other words, the test actively shapes our understanding of (and subsequently, approach to developing) AI – rather than passively measuring it. Goodhart’s law strikes again.
Both interpretations, though, buy into the idea that the test was formulated on the basis that it could, and should, be implemented in the real world. And that isn’t the case. To understand why, we could do worse than consider the ideas put forward in Bernardo Gonçalves’s excellent The Turing Test Argument. In it, Gonçalves shows how the paper was written in response to Turing’s debates with physicist Douglas Hartree, chemist and philosopher Michael Polanyi, and neurosurgeon Geoffrey Jefferson in the middle of the 20th century.
The essence of this debate, as we’ll see below, is that Turing believed that ‘thinking machines’ would eventually outstrip all of the cognitive abilities of humans. The others thought otherwise, which saw them butt heads with him in the press about humanity’s prospective relationship with AI.
University of Cambridge mathematician Douglas Hartree argued that computers would always be calculation engines incapable of acting in creative or unexpected ways. To make his case, Hartree cited Ada Lovelace's view that computers can only do what they are programmed to do in his 1950 book Calculating Instruments and Machines: "The Analytical Engine has no pretensions whatever to originate anything. It can do whatever we know how to order it to perform." So, a machine must be capable of performing tasks that it has not been specifically programmed to. Turing agreed, which is why he chose to connect his test with a ‘child–machine’ or what he called the ‘unorganised machine’ that could learn from experience.
Probably Turing’s most well respected critic was neurologist and neurosurgeon Geoffrey Jefferson, who set stringent criteria for machine intelligence that emphasised creativity. As the Times reported in 1949, he commented that “Not until a machine can write a sonnet or compose a concerto because of thoughts and emotions felt, and not by the chance fall of symbols, could we agree that machine equals brain — that is, not only write it but know that it had written it.”
Responding in the same newspaper on the next day, Turing, in typical cutting fashion, told the reporter “I do not think you can even draw the line about sonnets, though the comparison is perhaps a little bit unfair because a sonnet written by a machine will be better appreciated by another machine”. As we saw, Turing would go on to incorporate the idea of a machine writing a sonnet and being questioned about it in his imitation game.
Jefferson also argued, as Gonçalves explains, that hormones were crucial for producing facets of behaviour that machines could not replicate. In one example he said that, were it possible to create a mechanical replica of a tortoise, “that another tortoise would quickly find it a puzzling companion and a disappointing mate.” This issue—the relationship between gender and intelligence—was the motivating factor in Turing's decision to include gender imitation as part of his test, which represents a clear challenge to the idea that certain modes of behaviour were dependent on physiological conditions.
The final element of the debate that Turing responded to was from Hungarian-British polymath Michael Polanyi, who argued that human intelligence involves tacit knowledge that cannot be fully formalised or replicated by machines. He was unimpressed by Turing's one-time use of chess as a marker of machine intelligence, and proposed that chess could be performed automatically because its rules can be neatly specified. The idea led Turing to reconsider using chess as the primary task for demonstrating machine intelligence, which was instead replaced by conversation to better capture the breadth of human cognitive ability.
The point
What to make of the Turing test? We can make some headway by taking stock of the evidence. In response to criticism about the nature of machine intelligence and its ceiling, Turing designed his imitation game to address the following aspects:
It focused on learning and adaptability, countering Hartree's view of computers as calculation engines.
It incorporated language tasks like composing sonnets, addressing Jefferson's demands for human-like creative abilities.
It included gender imitation, subtly challenging Jefferson's views on the link between physiology and behaviour.
It used open-ended conversation rather than rule-based games like chess, addressing Polanyi's concerns about formalisability.
Turing was responding to critics who thought that machines would never demonstrate cognitive abilities close to that of a human. What to do when faced with detractors who believe that AI will never have either the indomitable spark nor special sauce that allows them to be truly intelligent? How should one deal with those who believe that a genuinely intelligent machine is a fiction?
Well, you set up a thought experiment explaining the conditions needed to prove them wrong. At the point at which Jefferson couldn’t tell the difference between machine poetry and the ‘real’ deal, his argument becomes meaningless. This is why Turing was interested in the conditions under which someone could call machines intelligent – and not the conditions under which intelligence could be measured.
But it was not to be. The space between thought experiment and practical experiment collapsed under the weight of its own cleverness. Turing may have been, for all intents and purposes, making a joke – but it was one that didn’t land. Worse still, it became a summit for AI researchers to climb and an open goal for philosophers to shoot at.
That, my friends, is the cruelty of the Turing test.
Illuminating! I am not as well versed in the debates of Turings day as you, but I always imagined his use of the word “thinking” was meant to evoke not just intelligence, but personhood. Even if explicit testing is beside the point, I think it’s reasonable to claim that modern llms “pass” the Turing test in a meaningful way. This poses a challenge (which I have taken to be the point of the thought experiment): On what basis are we denying the llms personhood?